


Being now very often in Brussels, I couldn’t miss the conference held at the European Commission, Translating Europe Forum 2018, on November 8th and 9th (I know, this post comes with some delay, sorry!). Yet, the main reason to attend was that finally a translation conference focuses on my main area of specialization, namely Big Data. I have been translating for ages about how Big Data is disrupting different fields, but never mine.
Attending this conference was definitely worthwhile, as I am sure you would agree after watching the recordings (available below). The panel I liked the most was the first-day plenary panel on neural machine translation (NMT), whose evolution has been astonishing and with which statistical-based machine translation simply cannot keep up. The panel agreed that the quality currently offered by NMT cannot be compared to professional human translation. Yet, more has happened in the last couple of years than in decades.
My personal take is that NMT is definitely here to stay and, provided it’s up to us to choose whether or not to use it to our advantage, we should see it as an ally to boost our productivity and not as the enemy. Of course, dealing with agencies trying to oblige us to become post-editors for peanuts instead of translators for decent fees is another story.
By the way, it is estimated that proofreading requires about 30% of efforts compared to translation, while post-editing would take approx. 65% provided that the quality is decent. This information can be used as a guideline for setting our post-editing fee per word, even if ideally we should always charge per hour afterwards (as Erik Hansoon rightly pointed out in his panel, agencies would generally not accept this method since they need to quote the project before it begins, not when it’s over).
Very interesting discussions have also been focusing on GDPR and related details which I hadn’t considered before, such as complicated questions like ‘To whom does the TM provided by the agency, edited by me and paid by the client belong?’ Curiously, one of the panelist was a lawyer specializing in nothing but copyright of TMs, but I must say that that panel brought up more doubts than clarity regarding GDPR among attendees! 😉
It has also been a great occasion to meet again or for the first time in person many wonderful colleagues, such as Alexander Drechsel, Maria Pia Montoro and María Galán (in the pictures below).


Below you can have a look at the programme of each day and watch all the video recordings.
Day 1




Below follow two of the three parallel sessions and their recordings (unfortunately for newcomers to the language industry, that recording is not available) .



Day 2

Below follow all the recordings of the three parallel sessions.





The icing on the cake was that a professional draughtsman artistically summarised each panel and keynote speech. Here are some of his works of art.
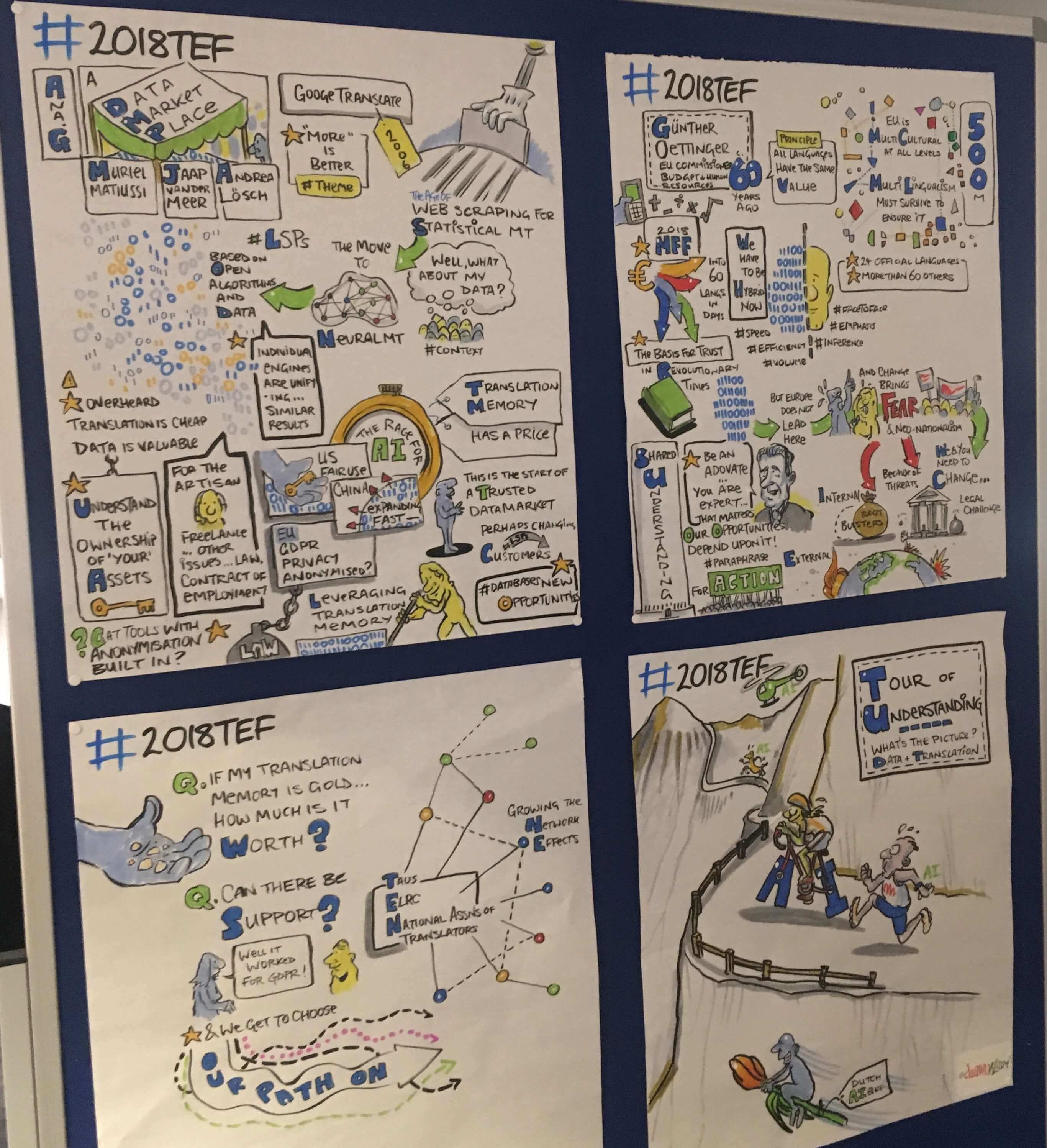
Finally, you can also read the event’s thread on Twitter: #2018TEF. I hope to meet you there next year, probably in November 2019!




